日处理20亿数据 实时用户行为服务系统架构实践
随着互联网业务的飞速发展,用户行为数据已成为企业决策、产品优化和精准运营的核心资产。面对每日高达20亿条数据洪流,如何构建一个稳定、高效、可扩展的实时用户行为服务系统,是技术团队面临的重大挑战。本文将深入探讨支撑如此庞大数据体量的系统架构设计、数据处理与存储服务的核心实践。
一、 系统架构概览:分层解耦与流批一体
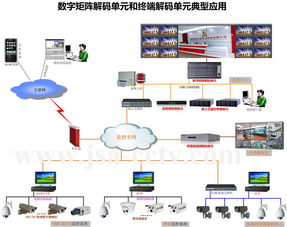
一个健壮的实时用户行为服务系统通常采用分层、解耦的架构设计,以实现高内聚、低耦合,便于独立扩展和维护。典型架构可分为四层:
- 数据采集层:负责从客户端(App、Web、小程序等)和服务端以轻量、高并发的方式收集用户行为日志。实践中常采用SDK埋点,通过HTTP或专有协议将数据发送至高性能网关(如Nginx集群),并立即转发至消息队列(如Apache Kafka/Pulsar),实现数据的异步化和缓冲,削峰填谷,确保上游数据生产不会冲击下游处理系统。
- 实时计算层:这是系统的“大脑”。数据从消息队列被实时消费,进入流计算引擎(如Apache Flink、Spark Streaming)。在此层完成核心的数据处理逻辑:数据解析、清洗(过滤无效/重复数据)、格式化、实时聚合(如PV/UV的分钟级统计)、复杂事件处理(CEP)以及基于规则的实时标签计算。Flink凭借其精确一次(Exactly-Once)语义、低延迟和高吞吐能力,成为处理20亿日数据量的首选。
- 存储与服务层:处理后的结果需要被高效存储并提供低延迟查询。这是一个多模存储的实践场景:
- 实时明细与特征存储:处理后的用户行为明细和实时更新的用户特征(如最近点击的品类、实时兴趣分数),通常写入高性能的NoSQL数据库(如HBase、Cassandra)或时序数据库(如InfluxDB),以满足毫秒级点查和范围查询需求。
- 聚合结果与指标存储:实时聚合出的分钟/小时级指标,可写入Redis或Doris/ClickHouse等OLAP数据库,用于实时大盘监控和即席分析。
- 离线备份与历史数据:所有原始数据及处理后的数据会同步备份到数据湖(如HDFS、Iceberg)或数据仓库(如Hive),用于离线深度分析、模型训练和数据审计。
- 查询与接口层:对外提供统一的API网关,封装底层存储的复杂性。根据业务需求,提供实时用户画像查询、行为序列查询、实时大盘数据接口等,通常通过RPC或RESTful API提供服务。
二、 数据处理实践:保证正确性、实时性与效率
处理20亿/天的数据量,每个环节都必须极致优化。
- 数据格式与压缩:采用高效的序列化格式(如Protobuf、Avro)并在传输过程中进行压缩(如Snappy、LZ4),显著减少网络带宽和存储占用。
- 窗口计算与状态管理:在流计算中,合理设置时间窗口(滚动、滑动、会话窗口)进行聚合。利用Flink的分布式状态后端(如RocksDB)可靠地管理海量中间状态,并设置合理的状态TTL以防止无限膨胀。
- 乱序与延迟处理:真实场景中数据难免乱序和延迟。通过设置Watermark(水印)机制和允许的延迟时间(Allowed Lateness),在保证计算效率的最大限度地保证结果的准确性。
- 资源弹性与容错:计算任务需要部署在YARN或Kubernetes上,实现资源的弹性调度。Flink的Checkpoint机制保证了作业状态的一致性快照,在故障时能快速恢复,确保数据不丢失、不重复。
三、 存储服务实践:多模融合与成本优化
存储是成本和技术挑战的焦点。
- 分层存储与生命周期管理:根据数据的热度(访问频率)实施分层存储策略。例如,最近7天的“热数据”存放在SSD介质的数据库中以保障性能;7天到90天的“温数据”可迁移至性能稍低但成本更优的存储;90天以上的“冷数据”则归档至对象存储(如S3、OSS)。通过自动化策略管理数据的整个生命周期。
- 索引与分区优化:针对HBase等存储,精心设计RowKey以实现数据均匀分布和高效查询;对ClickHouse/Doris表,采用合理的分区键和排序键,充分利用其向量化执行引擎的性能。
- 缓存加速:在存储层之上,广泛使用多级缓存。将最热的聚合结果和用户画像片段缓存在Redis集群中,甚至利用CDN缓存静态化的报表数据,将查询延迟降至最低。
- 统一查询服务:为了避免业务方对接多个存储系统,可以引入统一的查询引擎(如Presto/Trino)或构建一个元数据服务层,对业务提供逻辑上统一的“数据视图”,由查询服务自动路由到最合适的底层存储执行查询。
四、 监控与治理:保障系统平稳运行
如此大规模的系统,完善的监控和治理体系是生命线。
- 全链路监控:从数据采集、消息队列堆积、流处理延迟、存储读写延迟到API响应时间,进行全方位的指标监控和报警。
- 数据质量监控:建立数据校验规则,监控数据丢失率、重复率、字段填充率等关键质量指标,确保数据可信。
- 资源成本治理:持续监控和分析计算与存储的资源消耗,通过优化代码、合并小文件、清理无效数据、调整资源配置等方式,在保障服务等级协议(SLA)的前提下,有效控制成本。
构建日处理20亿数据的实时用户行为服务系统,是一项复杂的系统工程。其核心在于采用流批一体的架构思想,选择合适的技术组件,并在数据处理流水线和多模存储方案上进行深度优化。通过分层解耦、状态管理、资源弹性、分层存储和强力监控等综合实践,才能在应对海量数据冲击的提供稳定、实时、可靠的数据服务,真正将数据资产转化为业务价值。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/39.html
更新时间:2026-04-14 23:42:06