数据湖存储格式Hudi 核心原理与数据处理实践
引言
在大数据时代,数据湖已成为企业整合和分析海量多源异构数据的关键基础设施。传统数据湖在支持实时更新、增量处理和数据治理方面面临挑战。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,作为一种开源数据湖存储格式,它通过在Hadoop兼容的存储上引入事务、更新、删除和增量处理等核心能力,极大地提升了数据湖的实时性与可管理性。本文将深入探讨Hudi的核心原理,并结合实际场景,阐述其在数据处理与存储服务中的最佳实践。
一、Hudi的核心设计原理
Hudi的核心目标是高效地管理大型分析数据集,支持记录级的插入、更新和删除(即Upsert/Delete操作),同时提供快速的增量查询能力。其设计围绕两个核心概念展开:表类型和查询类型。
- 表类型(Table Types)
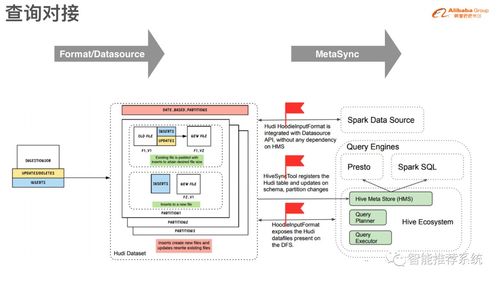
- Copy-On-Write(COW)表:此类型在写入时直接重写整个数据文件。当执行更新操作时,Hudi会找到包含该记录的文件,用包含更新后记录的新文件替换原文件,同时保留其他未更改的记录。这种方式读取性能最优,因为数据始终以列式格式(如Parquet)存储,但写入延迟较高,适合读多写少的场景。
- Merge-On-Read(MOR)表:此类型将更新数据写入到增量日志文件(通常是Avro格式),而基础数据文件(Parquet格式)保持不变。在读取时,Hudi会动态合并基础文件和增量日志,以提供最新的数据视图。这种方式写入延迟低,支持更快的Upsert,但读取时需要额外的合并开销,适合写多读少或需要近实时数据摄入的场景。
- 查询类型(Query Types)
- 快照查询(Snapshot Query):查询给定提交或压缩操作后表的最新快照。对于MOR表,它会即时合并基础文件和增量日志;对于COW表,则直接读取最新的数据文件。
- 增量查询(Incremental Query):查询自某个指定提交以来新增或更改的数据。这是Hudi的核心优势之一,能够高效地向下游系统(如ETL管道、流处理作业或数据仓库)提供增量数据流,无需全表扫描。
- 读优化查询(Read Optimized Query):仅查询MOR表中已压缩成列式格式的基础数据文件,提供最佳的读取性能,但数据可能不是最新的(存在延迟)。
Hudi通过其独特的时间轴(Timeline) 机制来管理所有对数据集的操作(提交、压缩、清理)。时间轴存储在.hoodie元数据目录下,记录了每次操作的时间戳、状态和类型,为事务一致性、数据版本控制和增量拉取提供了基础。
二、Hudi在数据处理与存储服务中的实践
将Hudi集成到数据处理流水线中,可以显著提升数据管理的灵活性和效率。以下是几个关键实践场景:
- 近实时数据摄入与更新
- 场景:来自Kafka、数据库CDC(变更数据捕获)流的实时数据需要被持续写入数据湖,并支持对历史记录的更新。
- 实践:使用Hudi的DeltaStreamer工具或直接使用Spark/Flink的Hudi连接器,将流数据以Upsert模式写入MOR表。通过设置合理的压缩调度(将增量日志合并到基础文件),可以在写入性能和读取效率之间取得平衡。这避免了传统上需要周期性重写整个分区的开销。
- 构建高效的增量ETL管道
- 场景:下游的聚合计算、指标分析或数据同步任务只需要处理自上次运行以来变化的数据。
- 实践:利用Hudi的增量查询功能。任务可以记录上一次成功处理的提交时间点,下次运行时通过Hudi的增量查询API,只拉取该时间点之后变更的数据(包括插入、更新和删除),极大地减少了数据处理量,提升了管道效率,并实现了准实时的数据新鲜度。
- 数据治理与生命周期管理
- 场景:需要遵守数据保留策略、删除特定用户数据以符合GDPR等法规,或清理过期数据。
- 实践:Hudi支持记录级的删除操作(软删除和硬删除)。通过简单的删除操作,并结合其内置的
clean服务(自动清理旧版本的文件和不再需要的增量日志),可以方便地管理数据生命周期,保持存储空间的高效利用,同时确保数据的合规性。
- 统一批流存储与服务层
- 场景:希望用同一套存储同时服务批处理作业(如每日报表)和交互式/流式查询(如实时仪表盘)。
- 实践:Hudi表天然支持这一需求。批处理作业可以使用快照或读优化查询获取一致性视图;流式查询或交互式分析引擎(如Presto/Trino, Spark SQL)则可以通过快照查询访问最新数据。Hudi与这些查询引擎深度集成,提供了开箱即用的高性能连接。
三、最佳实践与注意事项
- 键的设计:合理选择记录键(
recordKey)和分区路径(partitionPath)至关重要。记录键用于唯一标识和更新记录,分区路径则决定了数据的物理组织方式,影响查询过滤效率。 - 文件大小管理:配置合适的目标文件大小,避免产生过多小文件(影响查询性能)或过大的文件(影响写入和压缩效率)。利用Hudi的自动文件大小管理功能。
- 压缩与清理策略:针对MOR表,根据业务对数据新鲜度和查询性能的要求,设定合理的异步压缩策略。配置清理策略以删除旧的文件版本,控制存储成本。
- 索引选择:Hudi提供了多种索引(如布隆过滤器索引、全局索引等)来快速定位记录所在文件。根据数据分布和查询模式选择合适的索引类型,以优化Upsert性能。
结论
Apache Hudi通过创新的存储格式和表管理机制,将数据库的事务性、更新删除能力与数据湖的可扩展性、成本效益相结合。它不仅仅是存储格式,更是一套完整的数据湖管理与服务解决方案。深入理解其COW/MOR表类型和快照/增量查询模型,并结合实际业务场景进行合理设计与调优,能够构建出更加实时、高效和易于治理的数据湖,从而最大化数据资产的价值,赋能企业的数据分析与决策。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/57.html
更新时间:2026-04-17 16:16:56